
AI芯片大战全面爆发:从Nvidia霸主地位到巨头自研ASIC的反攻
英伟达超出所有预期,周三公布的利润大幅飙升,这得益于其在 AI 计算工作负载中表现突出的图形处理器(GPU)。但越来越多类别的 AI 芯片正在快速崛起。
各大超大规模云计算服务商纷纷开始设计自己的定制 ASIC(专用集成电路),从谷歌的 TPU,到亚马逊的 Trainium,以及 OpenAI 与博通(Broadcom)合作的计划。这些芯片更小、更便宜、更易获取,并可能减少它们对英伟达 GPU 的依赖。Futurum Group 的 Daniel Newman 告诉 CNBC,他认为未来几年定制 ASIC 的增长速度“甚至会快过 GPU 市场”。
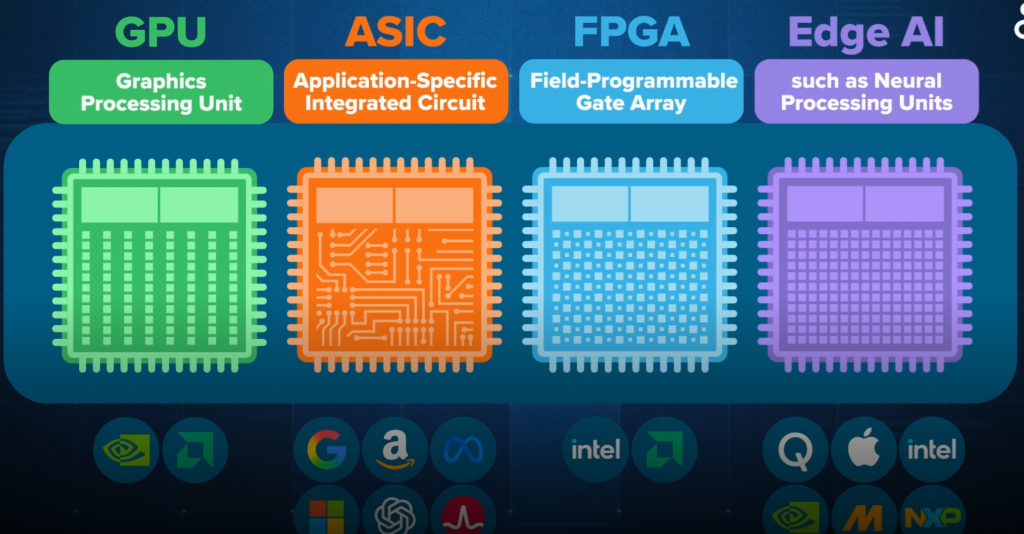
除了 GPU 和 ASIC,还有可编程逻辑门阵列(FPGA),它们可以在制造后通过软件重新配置,被广泛用于信号处理、网络和 AI 等各种应用。此外,还有一整类 AI 芯片专注于在设备端运行 AI,而不是云端运行。高通、苹果等公司一直在推动这些设备端 AI 芯片。
CNBC 采访了大型科技公司的专家和内部人士,解析如今拥挤的 AI 芯片市场及其分类。
【用于通用计算的 GPU】
GPU 最初主要用于游戏,但随着 GPU 的用途转向 AI 计算,英伟达因此成为全球市值最高的上市公司。过去一年,英伟达出货了约600万片最新一代 Blackwell GPU。
英伟达 AI 基础设施高级总监 Dion Harris 在 2025 年 11 月展示了由72块 Blackwell GPU 协同工作的 GB200 NVL72 AI 服务器系统。
GPU 从游戏走向 AI 的转折点发生在 2012 年,当时研究人员使用英伟达 GPU 训练了 AlexNet——这一成果被许多人视为现代 AI 的“大爆炸时刻”。AlexNet 参加了一场重要的图像识别竞赛。当时其他参赛者使用 CPU,而 AlexNet 使用 GPU 实现了前所未有的精确度,横扫全场。
AlexNet 的创造者发现,GPU 擅长的并行处理能力不仅能渲染逼真的图形,也非常适合训练神经网络——使计算机可以从数据中学习,而不是依赖人工编写规则。
如今,GPU 通常与 CPU 搭配使用,装配在服务器机架中部署到数据中心,用于云端 AI 运算。CPU 有少量高性能核心,用于通用顺序任务,而 GPU 拥有数千个更专注于矩阵运算的核心,可大规模并行计算。
正因 GPU 能同时执行大量运算,因此非常适合 AI 计算中的两大核心阶段:训练与推理。训练负责让模型从海量数据中学习,推理则让模型根据新信息做出判断。
GPU 是英伟达和主要竞争对手 AMD 争夺的核心业务。两者最大的差异之一在软件生态:英伟达 GPU tightly 依赖其自有软件平台 CUDA,而 AMD 则采用更开源的软件体系。
AMD 和英伟达将 GPU 卖给亚马逊、微软、谷歌、甲骨文、CoreWeave 等云服务商,这些公司再按小时或分钟租给 AI 企业。例如,Anthropic 与英伟达、微软的 300亿美元合作协议,就包括 1GW 的英伟达 GPU 算力。AMD 最近也获得了来自 OpenAI 和甲骨文的大规模订单。
英伟达也直接向 AI 公司和各国政府销售 GPU,包括韩国、沙特、英国等。公司向 CNBC 表示,一套装有72块 Blackwell GPU 的服务器机架售价约 300万美元,周出货约 1000 套。
Harris 回忆说,刚加入英伟达八年多前,他无法想象需求会爆发到如此程度:
“以前我们跟客户说一台机装八块 GPU,对方都觉得过头了。”
【为云计算优化的 ASIC】
在大语言模型爆发早期,训练主要靠 GPU,但随着模型成熟,推理变得更关键。推理工作可以在性能更简单、针对特定任务优化的芯片上完成,这就是 ASIC 的优势。
如果说 GPU 像一把功能全面的瑞士军刀,那么 ASIC 就像专用的单一工具——效率极高、速度极快,但只能执行某一种数学任务。
谷歌在 2025 年 11 月推出了第七代 TPU“铁木(Ironwood)”,距离 2015 年推出第一代 AI 定制 ASIC 刚好十年。
“ASIC 一旦刻进硅片就无法更改,因此灵活性是必须牺牲的,”《芯片战争》作者 Chris Miller 说。
英伟达 GPU 灵活、通用,被各家 AI 公司采用,但单卡售价可达四万美元,并且供不应求。而自行设计 ASIC 的前期成本更高,通常要从几千万美元起。
不过对于预算充裕的大型云计算公司来说,分析人士认为长期回报明显。
“他们想更好掌控自己的工作负载,”Newman 说,“但需求太大,他们也仍然必须同时与英伟达、AMD深度合作。”
谷歌是最早打造 AI 自研 ASIC 的大公司,2015 年推出第一代 TPU。谷歌称早在 2006 年就开始考虑研发 TPU,而到 2013 年发现如果不转向 ASIC,AI 计算需求将迫使数据中心数量翻倍。2017 年,TPU 也参与促成了 Transformer 的发明——这已成为现代 AI 的基础架构。
在推出第一代 TPU 十年后,谷歌发布第七代 TPU,Anthropic 将最多使用100万片 TPU 训练 Claude。Miller 表示,有人认为 TPU 技术上与英伟达 GPU 不相上下甚至更优。
“过去 TPU 基本只用于谷歌内部,”他说,“但很多人猜测未来谷歌可能开放 TPU 的更广泛使用。”
亚马逊 AWS 是第二家打造 AI 自研芯片的云服务商,在 2015 年收购以色列芯片初创 Annapurna Labs 后开始布局。AWS 在 2018 年推出 Inferentia,2022 年推出 Trainium,目前第三代 Trainium 有望在 12月发布。
Trainium 首席架构师 Ron Diamant 表示,亚马逊的 ASIC 在 AWS 环境下的性价比比其他厂商高 30% 到 40%。
2025年10月,CNBC 前往印第安纳州,对亚马逊最大 AI 数据中心进行首次摄像参访,Anthropic 的模型正在其上训练,使用 50万片 Trainium2 芯片。AWS 其他数据中心仍装满英伟达 GPU,用于满足 OpenAI 等客户需求。
制造 ASIC 并不简单,这也是许多公司依赖博通、Marvell 等芯片设计公司的原因。它们向客户提供知识产权、网络技术与设计能力。
“因此博通成为 AI 浪潮最大的受益者之一。”Miller 说。
博通参与打造谷歌 TPU、Meta 在 2023 年推出的 Training and Inference Accelerator,并将在 2026 年开始为 OpenAI 打造定制 ASIC。
微软也加入这一阵营,其自研 Maia 100 已部署在美国东部数据中心。高通、英特尔(Gaudi)、特斯拉(AI5)以及 Cerebras、Groq 等专注超大芯片与推理芯片的初创公司也都在投入。
在中国,华为、字节、阿里也在开发自研 AI ASIC,但先进设备出口管制构成挑战。
【设备端 AI:NPU 与 FPGA】
第三大类 AI 芯片是运行在设备端(非云端)的芯片,通常集成在设备主 SoC 中。设备端 AI 芯片降低了功耗和对云端的依赖,同时节省通信延时。
“你可以直接在手机上实时执行 AI,无需数据往返数据中心,”前白宫 AI 与半导体政策顾问 Saif Khan 说,“而且数据仍保存在用户设备上,更隐私。”
神经处理单元(NPU)是主流设备端 AI 芯片,高通、英特尔和 AMD 都在面向 PC 推出支持 AI 的 NPU。
苹果不使用“NPU”称呼,但其 MacBook 的 M 系列芯片内置神经引擎,最新的 iPhone A 系列也内置 AI 加速器。
“对我们来说,这更省电、更流畅,而且能更严格控制用户体验。”苹果平台架构副总裁 Tim Millet 在 9月向 CNBC 表示。
最新的安卓手机也在骁龙芯片中集成 NPU,三星 Galaxy 也有自家 NPU。NXP、英伟达等公司的 NPU 也被用于车辆、机器人、摄像头、智能家居等。
“目前钱主要花在数据中心,但未来情况会改变,因为 AI 将大规模分布在手机、汽车、可穿戴设备等终端中。”Miller 说。
FPGA 也可以在生产后由软件重新配置,比 NPU 或 ASIC 更灵活,但 AI 运算的性能与能效都较低。
AMD 在 2022 年以 490亿美元收购赛灵思后成为全球最大 FPGA 制造商,英特尔则因 2015 年收购 Altera(167亿美元)位居第二。
这些芯片最终都依赖一家制造商代工——台积电(TSMC)。
TSMC 在亚利桑那州建设了大型晶圆厂,苹果已承诺将部分产能搬到该地。英伟达 CEO 黄仁勋 2025年10月也表示 Blackwell GPU 已在亚利桑那“全面量产”。
尽管 AI 芯片领域竞争日益激烈,但撼动英伟达仍不容易。
“英伟达之所以拥有现在的地位,是因为它花了多年时间建立生态,”Newman 说,“他们赢下了开发者。”



